记住用户名密码
爬虫和数据清洗ETL
全屏阅读
etlpy是python编写的网页数据抓取和清洗工具,核心文件etl.py不超过500行,具备如下特点
爬虫和清洗逻辑基于xml定义,不需手工编写
基于python生成器,流式处理,对内存无要求
内置线程池,支持串行和并行处理
内置正则解析,html转义,json转换等数据清洗功能,直接输出可用文件
插件式设计,能够非常方便地增加其他文件和数据库格式
能够支持几乎一切网站,能自动填入cookie
github地址: https://github.com/ferventdesert/etlpy!
运行需要python3和lxml, 使用pip3 install lxml即可安装。内置的工程project.xml,包含了链家和大众点评两个爬虫的配置示例。
etlpy具有鲜明的函数式风格特征,使用了大量的动态类型,惰性求值,生成器和流式计算。
另外,github上有一个项目,里面有各种500行左右的代码实现的系统,看了几个非常赞https://github.com/aosabook/500lines
二.如何使用
当从网页和文件中抓取和处理数据时,我们总会被复杂的细节,比如编码,奇怪的Html和异步ajax请求所困扰。etlpy能够方便地处理这些问题。
etlpy的使用非常简单,先加载工程,之后即可返回一个生成器,返回所需数量即可。下面的代码,能够在20分钟内,获取大众点评网站上海的全部美食列表,总共16万条,30MB.
结果如下:
当然,以上方法是串行执行,你也可以选择并行执行以获取更快的速度:
可设置线程数,对获取的每个数据的回调方法,以及是否执行其中的执行器(下文有解释)。
etlpy的执行逻辑基于xml文件,不建议手工编写xml,而是使用笔者开发的另一款图形化爬虫工具,可以通过图形拖拽的方式设计并生成工程文件,这套工具也即将开源,因为暂时还没想到较好的名字。基于C#/WPF开发,通过这套工具,十分钟内就能完成大众点评的采集程序的编写,如果手工编码,一个熟练的python程序员可能得写一天。该工具生成的xml,即可被etlpy解析,生成跨平台的多线程爬虫。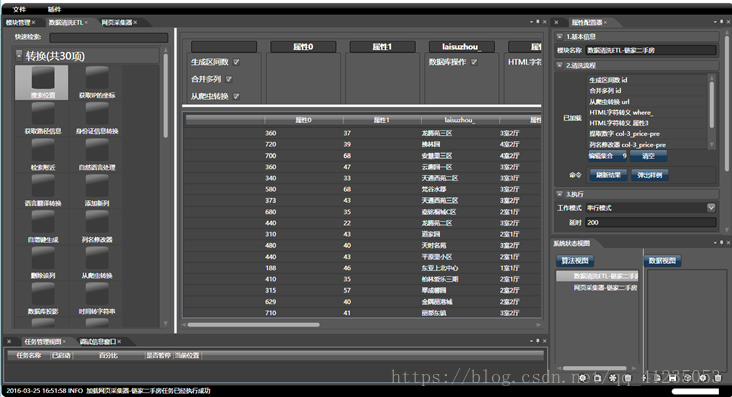 `
`
你可以选择手工修改xml,或是在代码中直接修改,来采集不同城市,或是输出到不同的文件:
三.原理
我们将每一步骤定义为独立的模块,将其串成一条链条(我们称之为流)。如下图所示:
![image_thumb[4]](https://www.tra56.com/wp-content/uploads/2020/08/366b669b07ed9689fb74457284de0f5f.png)
C#版本原理
鉴于博客园不少读者熟悉C#,我们不妨先用C#的例子来讲解:
其本质是动态组装Linq, 其数据链为IEnumerable。 IFreeDocument是 IDictionary
Python版本原理
python的生成器类似于C#的Linq,是一种流式迭代。etlpy对生成器做了扩展,实现了生成器级联,并联和交叉(笛卡尔积)
那么,生成器生成的是什么呢?我们选用了Python的字典,这种键值对的结构很好用。可以将所有的模块分为四种类型:
生成器(GE):如生成100个字典,键为1-100,值为‘1’到‘100’
转换器(TF):如将地址列中的数字提取到电话列中
过滤器(FT):如过滤所有某一列的值为空的的字典
执行器(GE):如将所有的字典存储到MongoDB中。
我们如何将这些模块组合成完整链条呢?由于Python没有Linq,我们通过组合生成器来获取新的生成器,这个函数定义如下:
如何定义模块呢?如果是先定义基类,然后从基类继承,这种方式依然要写大量的代码,而且不够Pythonic(我C#版本的代码就是这样写的)。
以清除字符串中前后空白的字符为例(C#中的trim, Python中的strip),我们能够定义这样的函数:
之后,通过读取配置文件,运行时动态地为一个基础对象添加属性和方法,从一个简单的TrimTF函数,生成一个具备同样功能的类。 整个etlpy的编写思路,就是从函数生成类,再最后将类的对象(模块)组合成流。
至于爬虫获取HTML正文的信息,则使用了XPath,而非正则表达式,当然你也可以使用正则。XPath也是自动生成的,具体的原理将在之后的博文中讲解。etlpy本质上是重新定义了抓取和清洗的原语,是一种新的语言(DSL),从而大大降低了编写这类应用的成本和复杂度。
(串行模式的QueryDatas函数,有一个etlcount的可选参数,你可以分别将其值设为从1到n,观察数据是如何被一步步地组合出来的)
三.例子
采集链家
先以抓取链家地产为例,我们来讲解这种流的强大:如何采集所有二手房数据呢?这涉及到翻页。

翻页时,我们会看到页面是这样变换的:
http://bj.lianjia.com/ershoufang/pg2/
http://bj.lianjia.com/ershoufang/pg3/
…
因此,需要构造一串上面的url. 聪明的你肯定会想到,应当先生成一组序列,从1到100(假设我们只抓取前100页)。
再通过MergeTF函数,从1-100生成上面的url列表。现在总共是100个url.
再通过爬虫转换器CrawlerTF,每个页面能够生成30个二手房信息,因此能够生成100*30个页面,但由于是基于流的,所以这3000个信息是不断yield出来的,每生成一个,后续的流程,如去除乱码,提取数字,保存到文件,都会执行。这样我们就获取了所有的信息。
不同的流,可以组合为更高级的流。例如,想要获取所有房地产的数据,可以分别定义链家,我爱我家等地产公司的流,再通过流将多个流拼接起来。
采集大众点评
大众点评的采集难度更大,每种门类只能翻到第50页,因此想要获取全部数据就必须想办法。
以北京美食为例,如果按不同美食的门类(咖啡厅,火锅,小吃…)和区域(海淀,西城,东城…)区分,美食页面就没有五十页了。所以,首先生成北京所有区域的流(project中“大众点评区域”,感兴趣的读者可以试着获取这个流看看),再生成所有美食门类的流(大众点评门类)。然后再将这两个流做交叉(m*n),再组合获取了每个种类的url, 通过url获取页面,再通过XPath获取对应门类的门店数量:
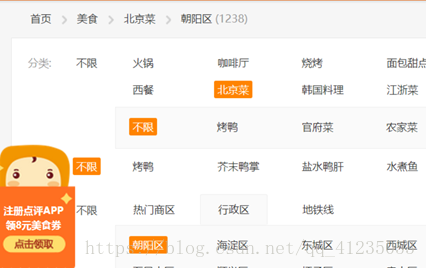
上文中的1238,也就是朝阳区的北京菜总共有1238家。
再通过python脚本计算要翻的页数,因为每页15个,那么有int(1238/15.0)+1页,记作q。 总共要抓取的页面数量,是一个(m,n,q)的异构立方体,不同的(m,n)都对应不同的q。 之后,就可以用类似于链家的方法,抓取所有页面了。
四.优化和细节
为了保证讲解的简单,我省略了大量实现的细节,其实在其中做了很多的优化。
1. 修改流,获取不同城市的信息
还以大众点评为例,我们希望只修改一个模块,就能切换北京,上海等美食的信息。
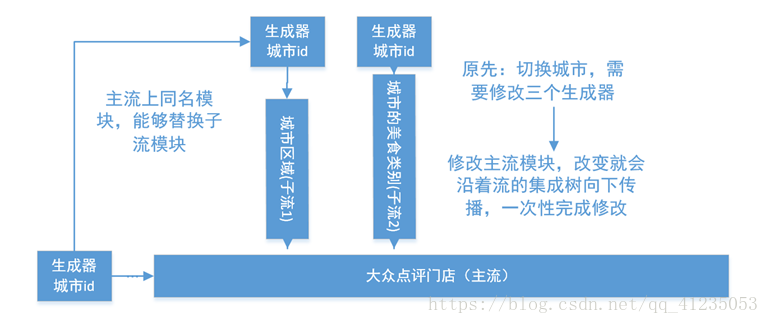
北京和上海的美食门类和区域列表都不一样,所以两个子流的队首的生成器,定义了城市的id。如果想修改城市,需要修改三个生成器。这太麻烦了,因此,etlpy采用了动态替换的方法。 如果主流中定义了与子流中同名的模块,只要修改了主流,主流就可以对子流完成修改。
2. 并行优化
最简单的并行化,应该从流的源头开始:
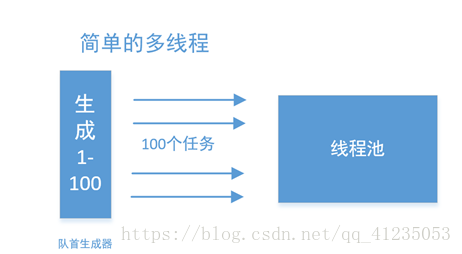
但如果队首只有一个元素,那么这种方法就非常低下了:
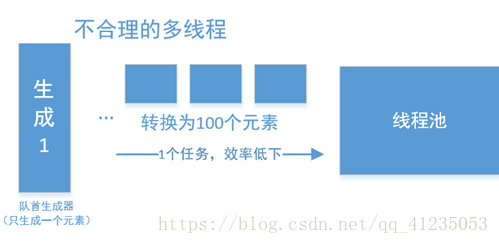
一种非常简单的思路,是将其切成两个流,并行在流中完成。
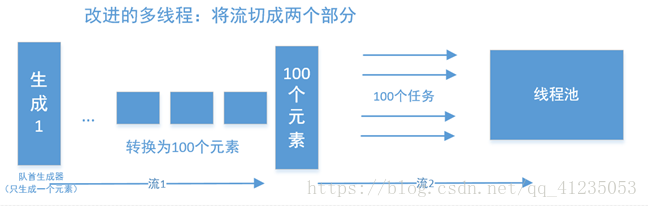
以大众点评为例, 北京有14个区县,有30种美食类型,那么先通过流1,获取420个元素,再以420个元素的基础上,进行并行,这样速度就快很多了。你也可以在14个区县之后插入并行化,那么就有14个子任务。etlpy通过一个ToListTF模块(它什么都不干)作为标识,作为流1和流2的分割符。
4.一些参数的说明
OneInput=True说明函数只需要字典中的一个值,此时传到函数里的只有dict[key],否则传递整个dict
OneOutput=True说明函数可能输出多个值,因此函数直接修改dict并返回null, 否则返回一个value,etlpy在函数外部修改dict.
IsMultiYield=True说明函数会返回生成器。
其他参数可具体参考python代码。
五.展望
使用xml作为工程的配置文件有显然的好处,因为能够被各种语言方便地读取,但是噪音太多,不易手工编写,如果能设计一个专用的数据清洗语言,那么应该会好很多。其实用图形化编程,效率会特别高。
etlpy的思想,来自于讲解Lisp的一本书《计算机程序的构造与解释》(SICP),书评在此:Lisp和SICP
可视化软件会在一个月内全部开源,解放程序员的大脑和双手,号称爬虫的终极武器。
» 固定链接:恒富网
» 《爬虫和数据清洗ETL》
目前有 0 条留言 其中:访客:0 条, 博主:0 条